
Image recognition technology has dramatically improved over the last decade. In particular, Machine Learning technique using Deep Learning along with adoption of Big Data have been improving the accuracy. For the field of document image processing, the objects to be handled are increased through application of Machine Learning, with CUTaccuracy ofCUT recognition as well as detection having been made even more accurate. We are conducting various research activities utilizing Machine Learning, targeting scene texts and historical documents.
Scene text is an important source of information, as borne out by the fact that methods for detecting and recognizing text from scene images have been studied for decades. In the past, text detection and recognition were handled as separate problems, with the method of recognizing after detection becoming mainstream. Recently, however, a method of simultaneous detection and recognition by Machine Learning has produced good results. We have proposed a method of detecting texts in the environment based on Machine Learning methods used for detection and recognition of general objects [1]. In order to cope with texts having various sizes and aspect ratios, we propose a method to incorporate multiple mechanisms for estimating candidate regions in a neural network. Using a public database, we confirmed that the accuracy of text detection improves. Furthermore, focusing on the fact that a large amount of training data is necessary to improve recognition accuracy, we proposed a method for generating various character images. Under this method, character data is generated by pasting stroke images using a character skeleton database.
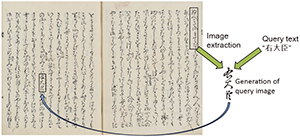
Japanese historical documents contain much historically important information; currently, research on constructing and utilizing database of Japanese historical documents is being conducted. One of the effective means of utilizing historical document images is to recognize individual characters then convert these into texts. Yet it is not easy to recognize various kinds of characters in historical document images with high accuracy. Therefore, instead of recognizing classical images, we are studying a method to realize retrieval by using the similarity of images [2]. Given a text, it generates an image that represents the text. By calculating the similarity with the image of the character string in the document, the area where the target text exists is detected (see Figure).
[1] Yoshito Nagaoka, Tomo Miyazaki, Yoshihiro Sugaya, Shinichiro Omachi. 2017. Text detection by Faster R-CNN with multiple region proposal networks. Proc. 7th International Workshop on Camera-Based Document Analysis and Recognition. 15-20.
[2] Chisato Sugawara, Tomo Miyazaki, Yoshihiro Sugaya, Shinichiro Omachi. 2017. Text retrieval for Japanese historical documents by image generation,” Proc. 2017 Workshop on Historical Document Imaging and Processing, 19-24.
